Ever since the HDMIPi KickStarter I’ve been very interested in watching the progress of other campaigns. I’m following four or five Pi-based campaigns at the moment. Are they going to make it? Are they not? It’s nice to keep an eye on things. But monitoring more than one or two wastes a lot of time. Wouldn’t it be nice if I could have a little computer and screen set up so that it checked these campaigns, say, once a minute, and reported on how they’re doing?
I know there’s a decent Python library called urllib2. I’ve used it before for simple stuff. How hard can it be? The answer is, not very hard. I had it up and running in basic form, for one campaign, in about 1.5 hours. But then spent a few more hours adding extras and making the output look nicer (as you do).
So How To Tackle Something Like This?
Like all programs, you break it into bits. Then write and test each bit before you go on to the next bit. Basically what we need to do is have the Pi…
- visit the Kickstarter page for the campaign we’re tracking
- search the html for the data we want
- extract the data we want
- display it nicely on the screen
- wait a while
- do it all over again
So the first thing we need to do is find out how to locate the data we want in the web page’s html. This requires a little bit of manual investigation work.
Finding The Data
Most browsers have a way to view the html source code of a page. Just visit the KickStarter campaign page you want to work with and make your browser view the source code. In Chrome on a Mac, it’s…
View > Developer > View Source
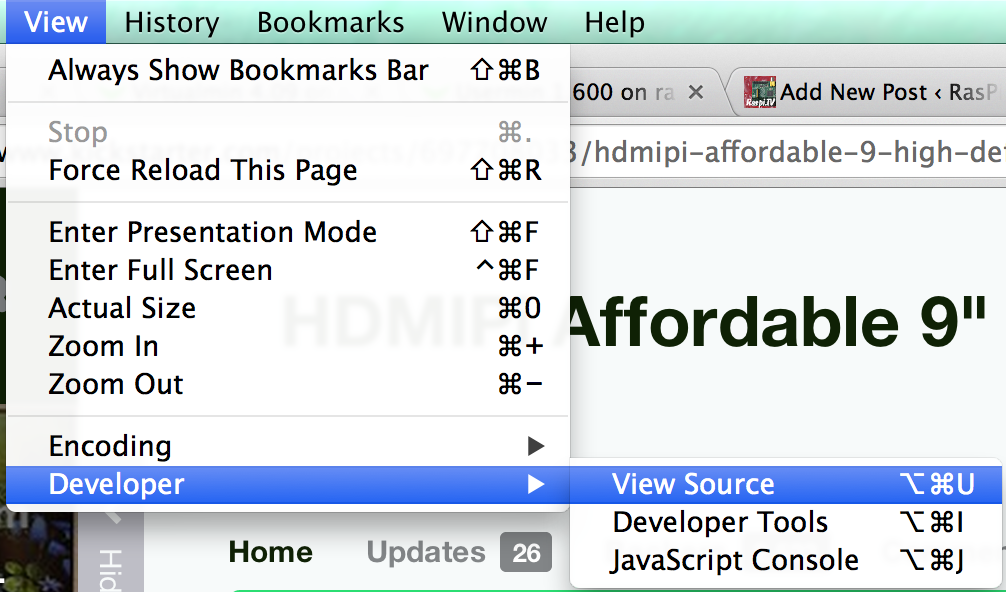
View Source HTML code
Looking at the source code, using CMD+F (CTRL+F on a PC) to search for the amount pledged, I found a line containing three useful bits of data. This is from line 842 of the HDMIPi KickStarter page
This contains most of the information I wanted. I also wanted to add in how much time was left over as well, and found that in another place, nearer the top of the page. (Line 88 of HDMIPi page)
Obviously the time left will be different for a live campaign (e.g. 16 hours or 24 days, rather than 0 seconds).
So this gives us a way of locating the information we want to extract from 2 lines in the HTML.
data-goal="55000.0"gives us the fundraising target in £ or $
data-percent-raised="4.750008363636363636363636364"multipling this by 100 gives us the percentage of the target raised so far. We’ll chop it to 2 decimal places in our code
data-pledged="261250.46"gives us the total amount pledged so far
twitter:text:time" content="0 seconds"tells us how much time the campaign has left to runAll we’ve got to do now is make the computer find, then split, slice and present the information how we want it. Sounds easy :)
Starting To Code
So having worked out how to find the information, or at least what lines it’s on, I needed to do a bit of homework about urllib2. I knew it could be used to load a web page, but needed a robust way of doing it. I found an excellent resource in the official Python documentation which gave me a whole snippet of code for this. It basically imports all the required parts of urllib2 and wraps the
urlopen()call in atry: except:block.This handles the situation when you lose your internet connection or if the web site doesn’t respond in time. Rather than crash the program, it handles the “Exception”, tells you what’s happening and tries again next time around. This is what I meant when I said “robust”.
from urllib2 import Request, urlopen, URLError req = Request(someurl) try: response = urlopen(req) except URLError as e: if hasattr(e, 'reason'): print 'We failed to reach a server.' print 'Reason: ', e.reason elif hasattr(e, 'code'): print 'The server couldn\'t fulfill the request.' print 'Error code: ', e.code else: # this is where you put the rest of your code to run after opening the web pageNow Let’s Add The URL
This code won’t really do anything unless we give it a value for
someurlwhich is the URL of the web page we want to load. So let’s add some code to the above to tell it the URL and get it to go through each line of the html file looking for the lines we want, and print them out on the screen when found.from urllib2 import Request, urlopen, URLError from time import sleep someurl= 'https://www.kickstarter.com/projects/697708033/hdmipi-affordable-9-high-def-screen-for-the-raspbe' req = Request(someurl) try: response = urlopen(req) except URLError as e: if hasattr(e, 'reason'): print 'We failed to reach a server.' print 'Reason: ', e.reason elif hasattr(e, 'code'): print 'The server couldn\'t fulfill the request.' print 'Error code: ', e.code else: the_page = response.readlines() # read each line of the html file into a variable 'the_page' for line in the_page: # iterate through the lines # checking for the ones we want to find & print them if 'twitter:text:time' in line: print line if 'data-goal' in line: print lineThis results in…
ks1.py program output
Now We Need To Split The Line
So we’ve retrieved the two lines we want. Now we want to extract just the data from them. How can we do that? There’s a very useful function called
split()which we’ll make use of.Explanation Of Split & Slicing
In line 20 of the Python script below, we use the code
days_left=line.split('"')[3]This is using
split()to split up the whole line…
<meta property="twitter:text:time" content="0 seconds">
…into pieces. It breaks everywhere it meets the"character (and removes the"). So it will break this line into a list variable containing the following elements…
<meta property=
twitter:text:time
content=
0 seconds
>If you print
line.split('"')it’ll look like this…
['<meta property=', 'twitter:text:time', ' content=', '0 seconds', '>']The first list element has position 0. This is called its index. We’re after the ‘0 seconds’ part which has index 3. So we ‘slice’ the list using [3], which gives us the list element in index position 3.
days_left=line.split('"')[3](This [3] is called ‘slice notation’)Here’s the full code…
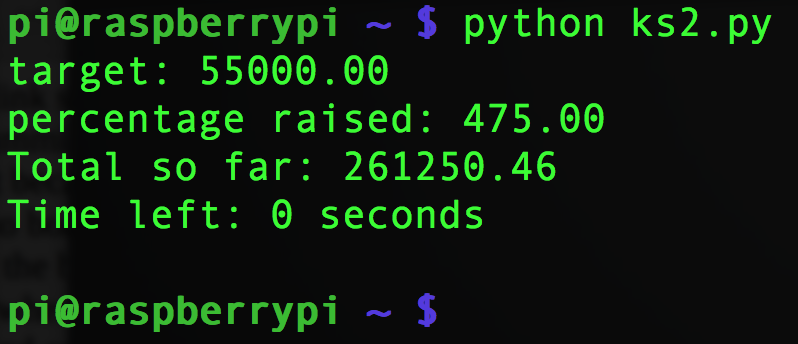
from urllib2 import Request, urlopen, URLError from time import sleep someurl= 'https://www.kickstarter.com/projects/697708033/hdmipi-affordable-9-high-def-screen-for-the-raspbe' req = Request(someurl) try: response = urlopen(req) except URLError as e: if hasattr(e, 'reason'): print 'We failed to reach a server.' print 'Reason: ', e.reason elif hasattr(e, 'code'): print 'The server couldn\'t fulfill the request.' print 'Error code: ', e.code else: the_page = response.readlines() # read each line of the html file for line in the_page: # iterate through the lines if 'twitter:text:time' in line: # check for lines we want to find & print them days_left=line.split('"')[3] if 'data-goal' in line: words = line.split(" ") # split line into 'words' for word in words: # iterate through 'words' if 'data-goal' in word: target = word.split('"') # split word at " character # make 2nd element a float print 'target: %.2f' % float(target[1]) # then truncate to 2 d.p. if 'data-percent-raised' in word: percent = word.split('"') print 'percentage raised: %.2f' % (float(percent[1]) * 100) if 'data-pledged' in word: amount_raised = word.split('"') print 'Total so far: %.2f' % float(amount_raised[1]) print 'Time left: %s' % days_left print ' ' # stick a blank line on the end break # break out of the loop once doneLines 26-34 make use of further splitting and slicing. We also need to convert the data we want into ‘float’ variable type before we can do anything mathematical with it.
print 'target: %.2f' % float(target[1])takes the 2nd element of ‘target’, converts it to a float and then.2fensures that only the first two decimal places are printed on the screen.Here’s What The Output Looks Like
ks2.py output
Obviously, you should change the URL in line 4 to track the live KS campaign you’re interested in.
The Story So Far
So far we’ve managed to…
- load a web page
- find the lines where our data is
- split out that data and retain just the parts we want by slicing
- convert it into something we can manipulate (float)
- truncate (shorten) to two decimal places and display it on the screen
That’s a very good start. We’ll take it further in the next part by…
- making the output more visually attractive
- adding some more campaigns
- putting it all in a continuous loop with a time delay

[…] Alex Eames wanted an easy way to track multiple Kickstarter campaigns. So, he decided to write one himself… As you do. He’s started a series on his blog, RasPi.TV. Read the first part here. […]
Nice example :)
The programmer part of me wondered if there was an API through which all this info is already available, but all I found was http://stackoverflow.com/questions/12907133/does-kickstarter-have-a-public-api (which says that it isn’t)
I’ve not used it myself, but I’ve seen http://www.crummy.com/software/BeautifulSoup/ recommended for screen-scraping HTML. Probably overkill for the simple example you’re using here though.
Personally I’d just use regexes (via Python’s re module) rather than splitting and slicing, but your code is obviously easier to understand for beginners.
print ‘Time left: %s’ % days_left
print ‘ ‘ # stick a blank line on the end
could be simplified to just
print ‘Time left: %s\n’ % days_left
It’s a shame that (‘”‘) appears to confuse the syntax-highlighting code used on your blog ;)
Be aware that screen-scraping code like this will probably need to be modified every time KS change/tweak the design of their website (which is why an API would be much better, *if* it were available).
Thanks Andrew. Yes I had a lot of trouble with the syntax highlighting plugin, which is why I had to use two different ones just to get the code to display correctly.
Yes – if KS change their pages, it’ll break the script. But hopefully we’ve taught all the skills here that will be needed to fix it quickly :)
I remember Regex from PERL. I must admit, I always found it really hard to use. At least with splitting and slicing I can understand what I’m doing and build up one bit at a time.
AndrewS – Could you please give an example in regex, thanks.
Alex – Thanks! I learned new stuff from this.
Great! That’s the hope. It should be applicable to getting info from any web page, if tweaked.
Here’s a simple (?) example
import re line = '<div class="num h48 no-margin" id="pledged" data-pledged="261250.46" data-percent-raised="4.750008363636363636363636364" data-goal="55000.0"></div>' m = re.match('<div\s+class="[^"]+"\s+id="pledged"\s+data-pledged="(\d+(\.\d+)?)"\s+data-percent-raised="(\d+(\.\d+)?)"\s+data-goal="(\d+(\.\d+)?)"></div>', line) if m: amount_raised = m.group(1) percent = m.group(3) target = m.group(5) print 'target: %.2f\npercentage raised: %.2f\nTotal so far: %.2f' % (float(target), float(percent) * 100, float(amount_raised))Regexes always look *really* horrendous when you first see them, but are simple when you break them down into their sub-parts:
\s+ means match one-or-more whitespace characters (which is always more flexible than just matching on a single space)
[^”] means match any character that _isn’t_ a double-quote
[^”]+ means match one-or-more characters that aren’t double-quotes
“[^”]+” means match a double-quote, followed by one-or-more characters that aren’t double-quotes, followed by another double quote, i.e. match any arbitrary string, all contained in double quotes
\d+ means match one-or-more digits (numbers)
\.\d+ means match a full-stop, followed by one-or-more digits (numbers)
\d+(\.\d+)? means match one-or-more digits, optionally followed by a full-stop and one-or-more digits, i.e. match 5, 136, 0.4, 1.7, 45.982, etc.
For more info, be sure to have a look at https://docs.python.org/2/howto/regex.html
[…] MT – https://raspi.tv/2014/programming-a-kickstarter-tracker-in-python-part-1 […]
[…] Ever since the HDMIPi KickStarter I've been very interested in watching the progress of other campaigns. I'm following four or five Pi-based campaigns at the moment. Are they going to make it? Are … […]
[…] my previous blog post I started a series on how to program a KickStarter tracker. That will continue soon. In the meantime, one of the KickStarter campaigns I’ve been […]