
In my previous blog post, I showed you my Python based vocabulary tester and suggested some ways it could be “taken further”.
You probably won’t be overly surprised to hear that I have taken it a bit further myself. Actually, I’ve taken it rather a LOT further, but this blog article is to show you the next couple of steps.
Let’s Compile a List
The first, fairly easy, tweak I made was to store the words I don’t know in a file. I figured it would be good to make a list of these so they can be looked up or used in some way. Each time I run the vocab checker script I get a handful of new ‘unknown’ words. But what can we do with those once we’ve stored them?
Let’s Look up the Definitions
I thought it would be nice if we could try to automate some kind of dictionary lookups of the unknown words. Doing this by computer would be much faster than using a paper-based dictionary, so we can hopefully improve our vocabulary as well as measuring it. It’d be great to be able to list the definitions of the unknown words at the end.
And after that we could do other stuff with it too, but for today we’ll focus on storing and defining.
Tweak #1 – Storing the Unknown Words
Storing data in a file is easy. We only need three new lines of code to achieve this. Lines 43-44 of our original script are replaced by…
add_unknowns = open("unknown_words.txt", "a")
for word in unknown_words:
print(word)
add_unknowns.write(word+"\n")
add_unknowns.close()
So we open a file called unknown_words.txt with the "a" option. This means we append (add to the end) our unknown words to the file. If the file doesn’t exist, it’s created in the same directory as our script.
Then we loop through the words, printing each one on the screen print(word) and writing it to unknown_words.txt add_unknowns.write(word+"\n")
When we’ve finished, we close the file add_unknowns.close()
If you took vocab.py from Github, you may see that I already sneaked that code into the script without documenting it in the previous blog.
Once you’ve run vocab.py you should find the unknown_words.txt file looking something like this…
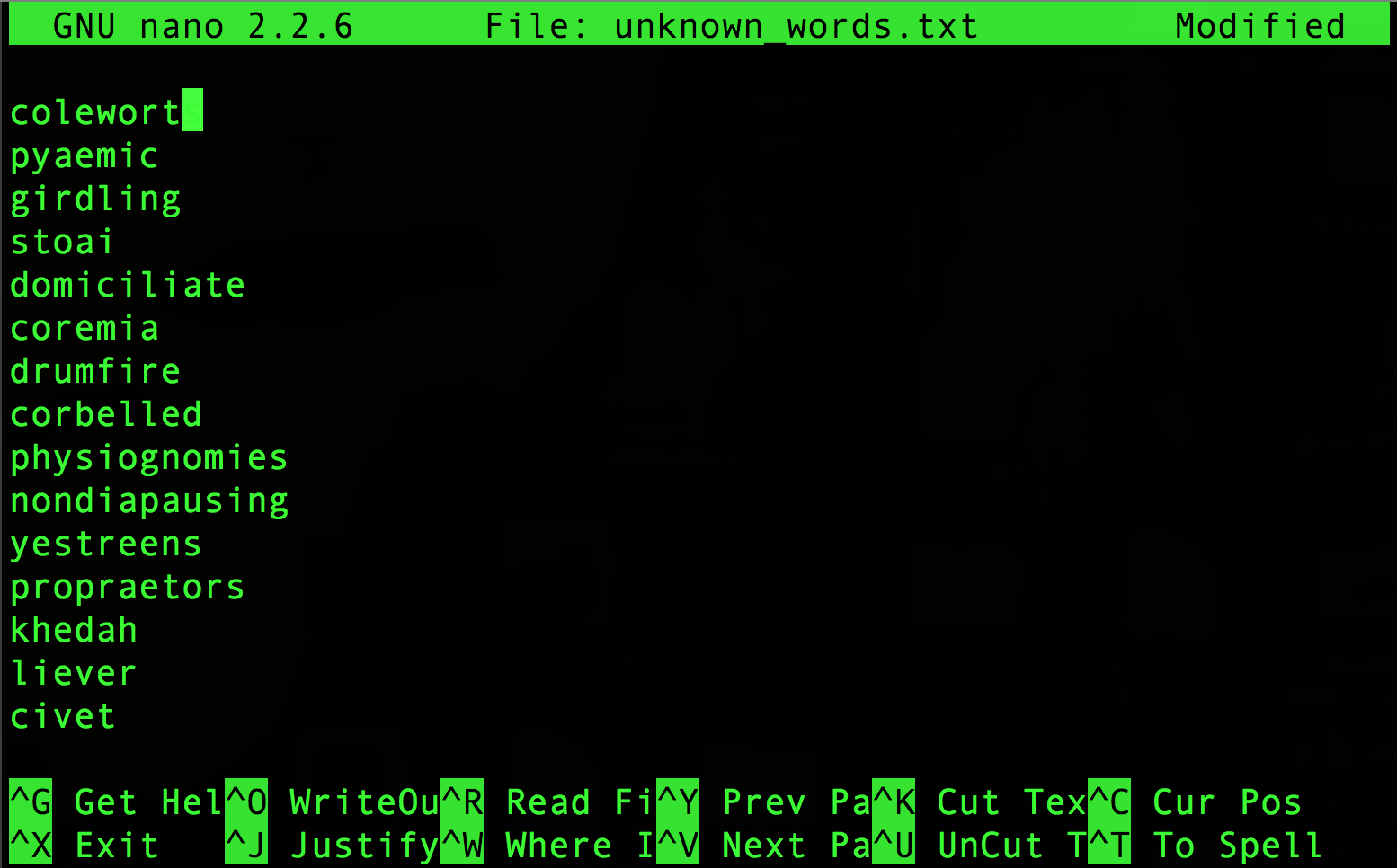
unknown_words.txt should look like this
Tweak #2 – Defining
Storing our words was the ‘easy win’, now let’s do something with them. I went down a ‘blind alley’ at first. I looked online at dictionary APIs and their number and complexity made me swoon. So I was delighted to find a Python library called PyDictionary. I installed it and spent time fixing it (the PyPy was out of date and it needed a manual change to a file to get it working right). It then worked, but there was a problem…
Pydictionary didn’t have definitions for most of my unknown words
…so I needed a better solution. I was still put off by the APIs and I noticed that Dictionary.com held definitions for most of the words. So I decided I would borrow and adapt some ‘web page scraping’ code from my KickStarter tracker. I got it working and Andrew Scheller helped me with a few tweaks to tidy it a little and make it work in either Python 2 or 3. The code is on GitHub, but also reproduced below…
from __future__ import print_function
try:
# Python2
from urllib2 import Request, urlopen, URLError
except ImportError:
# Python3
from urllib.request import Request, urlopen, URLError
wordlist = list(open("unknown_words.txt", "r"))
words = [x.strip() for x in wordlist] # remove \n line ends
base_url = 'http://www.dictionary.com/browse/'
def lookup(keyword): # word lookup function
# build url to lookup
url = base_url + keyword
req = Request(url) # grab web page
try:
grab_page = urlopen(req)
except URLError as e:
if hasattr(e, 'reason'):
print(keyword, e.reason)
undef_unknowns = open("unknown_words_notfound.txt", "a")
undef_unknowns.write((keyword + "\n")) # log unfound word in file
undef_unknowns.close()
elif hasattr(e, 'code'):
print('The server couldn\'t fulfill the request.')
print('Error code: ', e.code)
else:
web_page = grab_page.readlines() # read web page lines
for line in web_page:
line = line.decode('utf-8')
if '<meta name="description"' in line: # find required line
splitline = line.split('"')
for entry in splitline: # extract bits we want
if 'definition,' in entry:
write_line = keyword+": "+''.join(entry.split('definition, ')[1:])
print(write_line)
write_line +="\n"
def_unknowns = open("unknown_words_defs.txt", "a")
def_unknowns.write(write_line) # write word + def'n to file
def_unknowns.close()
for word in words:
lookup(word)
print()
You can get the code from Github https://github.com/raspitv/vocab or using
git clone https://github.com/raspitv/vocab.git
You can run the script with python3 dict_scraper.py
Let’s walk through the code:
Lines 1-7: import libraries and deal with Python2/3 compatibility
Lines 9-10: read our unknown word list into wordlist and strip off the line breaks
Line 12: set the base_url of our lookups
Lines 14-43: Define a function which does the bulk of the work
Lines 44-46: Main loop runs our lookup() function on each word and prints a blank line after each
Let’s look at our lookup() function…
Lines 16:17 Append our keyword to the base_url and fix the command to look up the web page
Lines 18-19: Try to grab the web page
Lines 20-25: If word not found, log in another file called unknown_words_notfound.txt for future use
Lines 27-29: If it’s another error, show us what it is
Lines 30-43: Otherwise, it’s worked, so let’s process the page and extract the data we want
Lines 31-33: Read the web page and look at each line, converting it to utf-8 for Python 3 compatibility as we go
Lines 34-37: Find the line we want, which contains the ‘meta description’ tag (this was originally found by looking at the source code of a dictionary.com definition page and working out where the concise definition could be reliably found)
Lines 38-43: Once we’ve found our definition line, split out the part we want, print the definition on the screen, and write it to the file unknown_words_defs.txt for future use.
Here’s a 1 minute screencast of what happens when you run it…
…and you end up with…
- A screen showing definitions and “not found” notifications
- A file of definitions
unknown_words_defs.txt - A file of words that weren’t found
unknown_words_notfound.txt
Here’s what they look like…
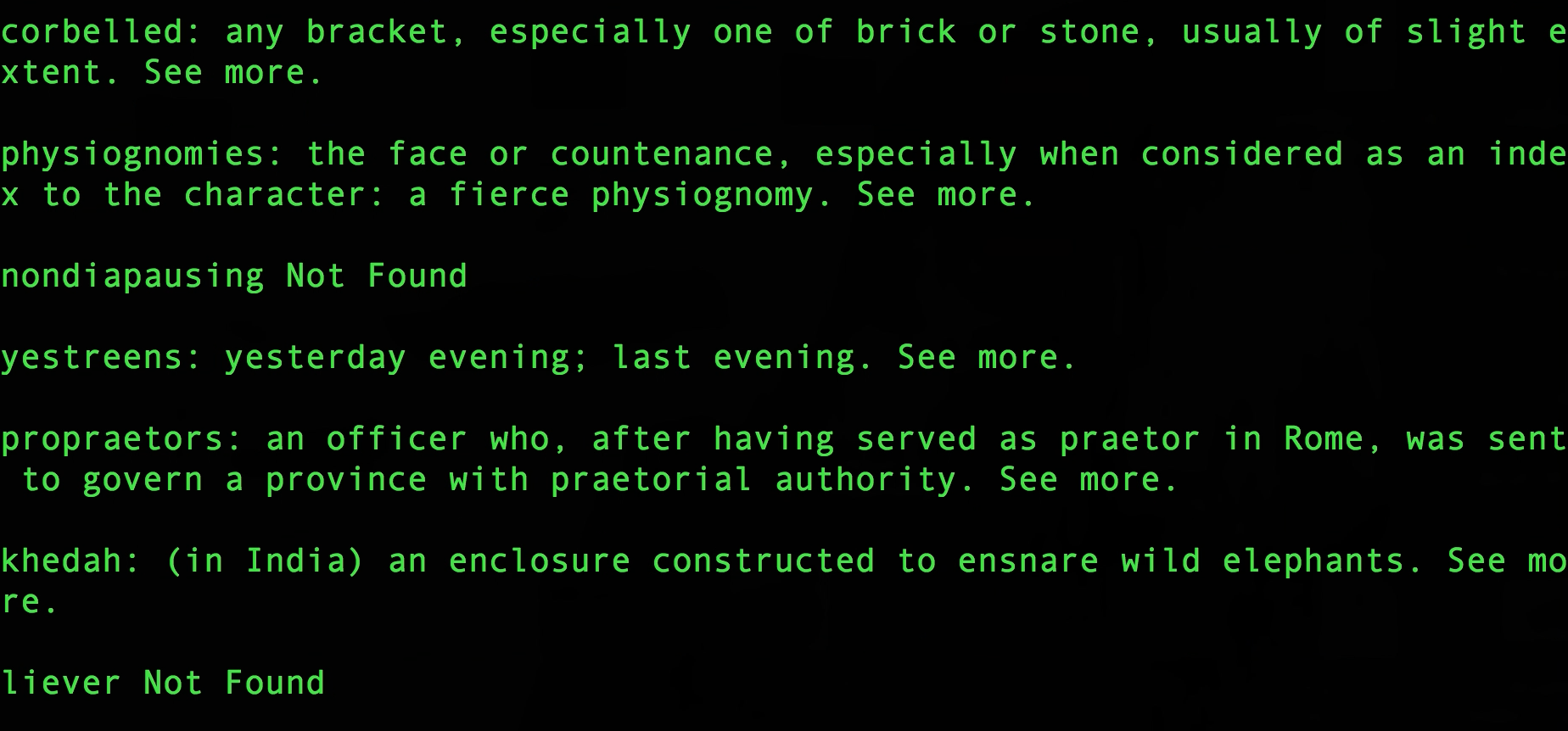
Screen Output of script
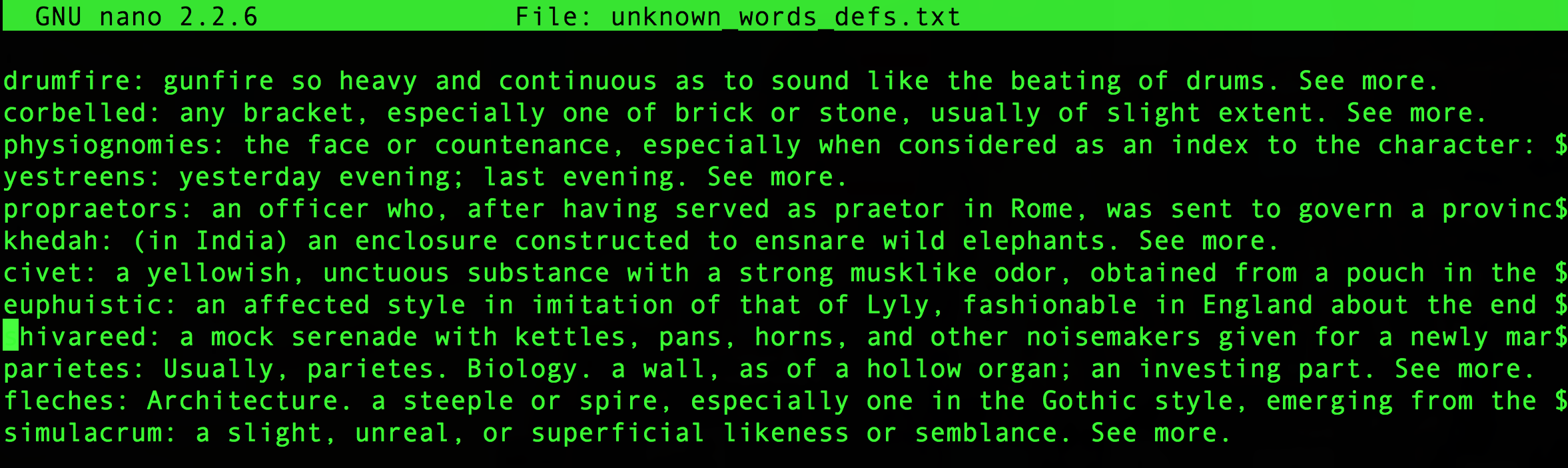
unknown_words_defs.txt should look like this
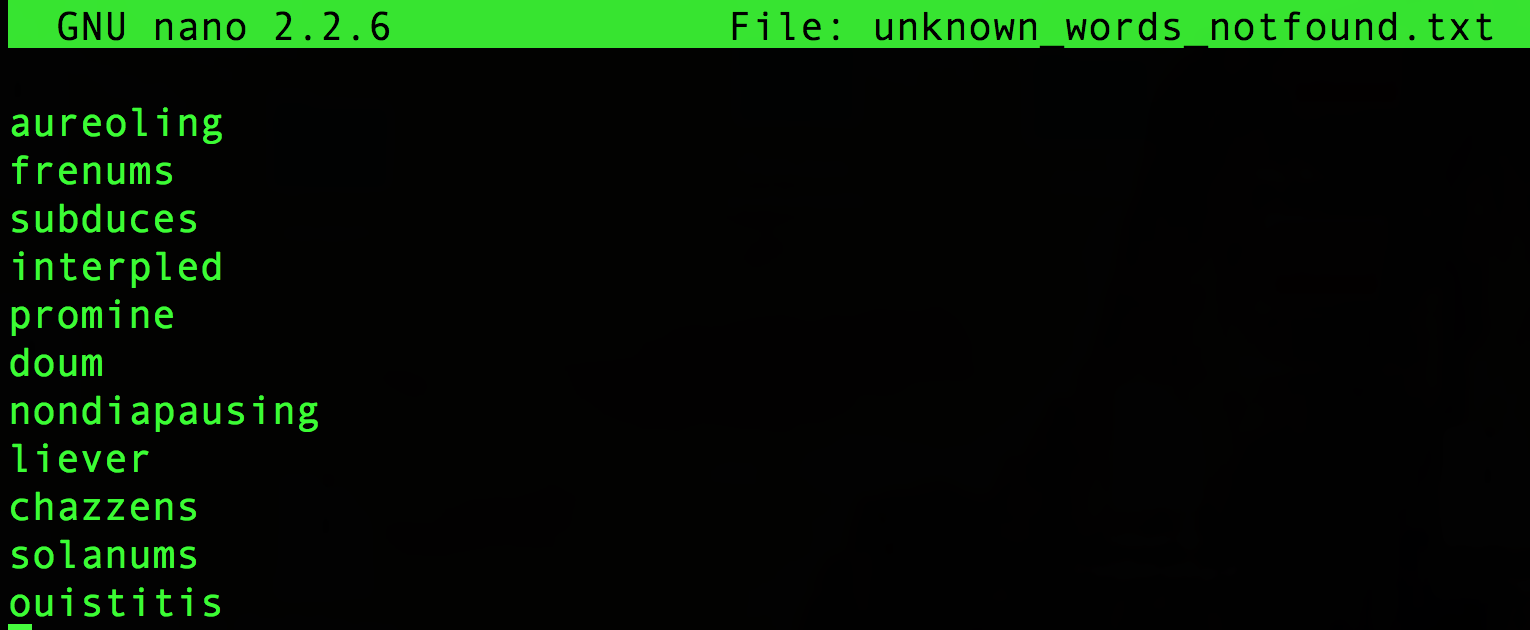
unknown_words_notfound.txt should look like this
Note: It doesn’t reset (empty) the file unknown_words.txt so you will have to do this manually if you want to.
What Next?
I mentioned a possible ‘endgame’ in the original blog post. A word of the day twitterbot. I’ve actually already done this (@PiWordoftheDay) and it works like this…
- I use the vocab tester script to generate some ‘fancy’ words and save them in a file
- The above dictionary lookup script gives us the definitions in another file
- A third script (which I may talk about in the next blog post) tweets a word definition three times a day from the stored list
The idea is to learn three new words each day. If you fancy learning three new words per day, just follow @PiWordoftheDay on twitter.
Here’s a recent one…
tularemias: a plaguelike disease of rabbits, squirrels, etc., caused by a bacterium, Francisella https://t.co/Cpl7eHuE4f
— PiWordoftheDay (@PiWordoftheDay) November 9, 2016
I guess another enhancement would be to not add new words to unknown_words.txt, if the file already contains the word.
But OTOH if you learn all of the unknown words, a word should never be “unknown” more than once ;-)