
The other day I read an article on the BBC website which suggested a method to estimate your vocabulary. Essentially, you sample 20 pages of your dictionary and note down how many words you know on each page. Then you add up the total, divide by 20, then multiply this by the number of pages in your dictionary. This gives you an estimate of your vocabulary. (Results will depend on the number of words in the dictionary, so use the largest you have.)
This seemed like a good idea, so I tried it. I used a 25-year old Oxford Advanced Learner’s Dictionary with 1492 pages.

1492 page Oxford Advanced Learner’s Dictionary
I also used Python to sample the page numbers for me…
import random
for x in range(20):
random.randint(1, 1492)
I used the above code in a live session and it gave me…
603, 184, 725, 690, 1492, 1406, 1095, 1063, 792, 413
1380, 869, 1278, 623, 914, 455, 673, 757, 177, 1274
Even though I knew nearly every word on every page, I ended up with a score (18,500) that was significantly lower than that of a typical graduate (23,000 according to their scale).
“That can’t be right.” I thought. “I’m not a lexicographer, but I have absorbed “the lingo” in quite a lot of subjects over the years (Chemistry, Car Mechanics, Computing, Carpentry, Electronics, Business – to name but a few).”
It is true that, in my writing, I have a predilection for preventing proliferation of pontificatory prose. But I do love a good pun, alliteration or acrostic. I want my work to be understood by smart children and also non-native English speakers. But I reckon I should know at least as many words as an average graduate, since I graduated in 1992 and have continued to “learn new things” over the last 24 years.
So What Went Wrong?
It could be a sampling error. Maybe 20 pages is too small a sample for a 1492 page dictionary and Python picked too many with a small number of words on? Some pages in the sample had just 6 words on. Others had as many as 30. Maybe my dictionary is too small?
Or maybe I’m just looking for a way to pump up my score (and my ego)? WJDK. Maybe I’m not as literate as I thought? In reality it doesn’t matter much either way – it’s just a bit of fun.
So I thought it would be fun to see if I could knock up a Python script to help do the job for us instead of all that tedious counting.
Let’s Write a Program
I thought about how this might be achieved and realised I already had some of what I needed in the scripts I wrote for testing multicore use of Pi2.
This test suite analyses and rearranges the “Scrabble Word List” (172820 entries). We’ll only use a little bit of the script, but the word list is EXACTLY what we need for our vocabulary testing application. At least, I thought it was.
The Scrabble Word List ends up giving a really high number. A quick look inside the file shows you why this is. For starters, nearly every word in the list is present in singular and plural forms. And many words have multiple derivative forms as well, e.g…
- abbreviate
- abbreviated
- abbreviates
- abbreviating
- abbreviation
- abbreviations
- abbreviator
- abbreviators
How Can We Shorten the List? (See what I did there?)
In an ideal world we’d use only a list of “stem” words, but I couldn’t easily find one. So, from my results, I figured out a “rough guess” correction factor of around 5. I got this from a quick visual inspection of the list and ‘guesstimated’ that the average word had about 5 derivatives.
Then I decided to be more scientific about it and sampled 100 words from the list using my program, looked up how many derivatives each one had, and took the average. It turned out to be 6.75. That number is quite subjective though as I had to make decisions about what constitutes a derivative and what is a separate word. Some words like “special” had 54 derivatives; “express” had 53. Most of the others had 2-7 variants.
That process was quite educational in itself. I mean, who knew that as well as chernozem, you could also have chernozemic and chernozems?
What About the Code?
So here is the code I came up with. It’s only 44 lines of Python. It should run on any computer that has Python 2 or 3.
The script reads in a .txt file containing the Scrabble Word List, then displays a word selected at random. The user informs the program know whether or not they can define each word. This process is repeated 100 times. From the results, an estimate of your vocabulary is calculated, and the words you didn’t know are also displayed. It takes about 3 minutes to run through 100 words.
#!/usr/bin/python
# Alex Eames RasPi.TV https://raspi.tv/?p=9652
from __future__ import print_function
import random
try:
# Python2
input = raw_input
except NameError:
# Python3
pass
iterations = 100
correction_factor = 6.75
recognised = 0
unknown_words = []
# Open the word list and read into Python list
results = list(open("wordlist.txt", "r"))
clean_lines = [x.strip() for x in results] # remove \n line ends
lines = len(clean_lines)
for x in range(iterations):
new_word = random.choice(clean_lines)
print(new_word)
prompt = ""
if x % 10 == 0:
prompt = "<Enter> = recognise, anything else = don't recognise "
answer = input(prompt)
if answer == "":
recognised += 1
else:
unknown_words.append(new_word)
vocab = int(recognised / float(iterations) * lines)
print("recognised: ", recognised, "out of ", iterations)
print("that's ", recognised / float(iterations) * 100, "%")
print("Your 'Scrabble list' vocabulary is: ", vocab)
print("Your 'Corrected' vocabulary is: ", int(vocab / correction_factor))
print("Here are the words you said you didn't know...")
for word in unknown_words:
print(word)
Lines 3 & 6-11: ensure script will run on both Python 2 and 3
Line4: load up the random module so we can choose random numbers
Lines 13-16: set initial values for variables (iterations and correction_factor are tweakable)
Lines 19-21: read the file wordlist.txt into a list variable clean_lines of length lines
Lines 23-33: pick a random word and display it, wait for user input, then process data and iterate until complete
Lines 35-41: calculate scores and display the results
Lines 43-44: display the ‘unknown words’
Where Can I Get It?
To run this on your Pi…
cd
git clone https://github.com/raspitv/vocab/
cd vocab
python3 vocab.py
What are the Rules?
When you run the script (python3 vocab.py) it will display a word on the screen. Your job is to hit “Enter” if you can define that word. I’m strict here – if you can define it, you know it. If you can’t define it, you don’t know it. If you can guess it, but have never come across it before – you still don’t know it.
So if you can define the word, you hit “Enter“. If you can’t, you hit any other key and then “Enter“. The script will show you 100 random words and calculate your score according to that.

This is what you see when you run the script
If you want to change the number of words asked, change the value of iterations in line 5. A larger value will give more accuracy at the expense of time.
When you’ve completed your 100 words, it calculates your score and displays the words you didn’t know…
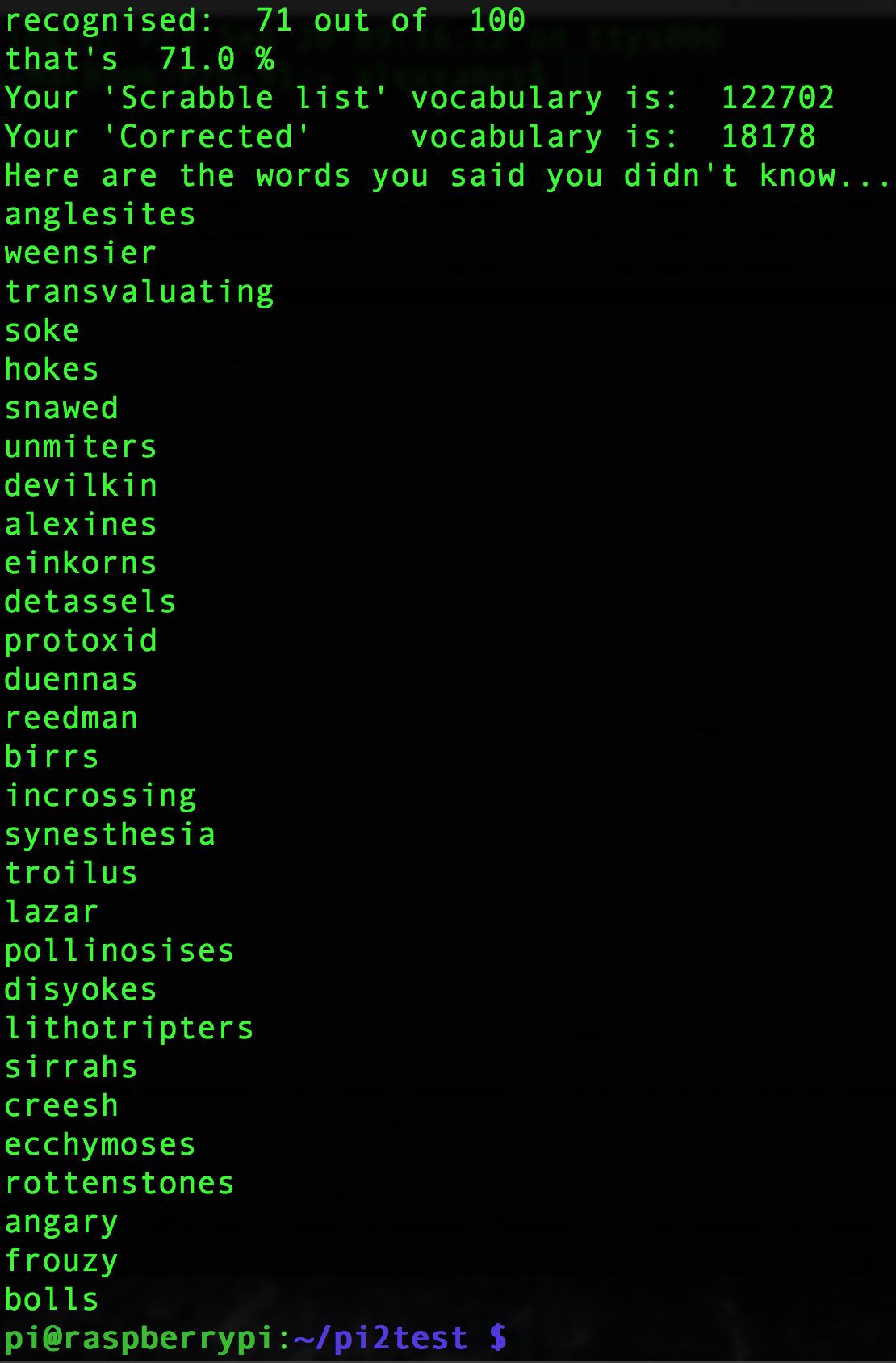
Output of a test run
I feel like I should have known that an alexine is a “defensive proteid”, but somehow that has escaped my notice thus far. If you’re a curious person, you’ll find that this process will make you want to look up some of the words you’ve never seen before – either to check your guess is correct, or just “what the heck is that?”
e.g. lithotripter is: A device that pulverizes kidney stones and gallstones by passing shock waves through a water-filled tub in which the patient sits. Who knew? Certainly not me, but I do now.
Take It Further?
Here’s a few ideas for how you could take it futher…
- Find a more suitable word list so correction factors are not needed
- Change the word list to another language
- Use your own specialist lexicon and make it into a themed quiz
- Add the words you don’t know to a separate file
- Have it look up the words you don’t know and provide definitions
- Display a different definition each time you log on
- Make a twitterbot to tweet one of your unknown word definitions per day
How Did You Score?
I’m ambivalent about the correction factor and the way I implemented it. I’d love to get hold of a comprehensive list of stem words to do this test properly. I don’t know if such a thing exists, but it isn’t worth the time to go through 172820 entries de-duplicating derivatives. It would take weeks.
But if we all use the same script with the same word list we should get comparable results.
My scores are generally between 18,000 and 20,000 (70-80%). I would expect increasing the number of iterations would smooth out variability here.
I’d be interested to see results from other people if you try it and feel like posting them. It would also be useful to state your general level of education and whether or not English is your first language. Go on! Be brave! Try it out and share your score. There’s no shame in not knowing a word.
Ahhh, the irony of writing a blog post all about vocabulary, and consistently spelling ‘derivatives’ incorrectly ;-)
GAH! I really should know that one since my 2nd year ‘essay week’ topic was “Derivatisation of Amines for HPLC”.
I shall correct it but leave your comment in place. What was your score? ;p
71%
recognised: 73 out of 100
that’s 73.0 %
Your ‘Scrabble list’ vocabulary is: 126158
Your ‘Corrected’ vocabulary is: 18690
Here are the words you said you didn’t know…
Lovely. Some of those seemed very familiar: are chelae the atoms that do the chelating? is ‘isopropyls’ the collection of chemicals like isopropyl alcohol? is a countian someone that comes from a county? As you say I’m going to have to look some words up!
Here are the words you said you didn’t know…
crevalles
cateran
clumbers
skosh
censused
displodes
ideative
totipotent
haplonts
raucity
countian
certiorari
chelae
isopropyls
medusal
tergiversations
keelsons
prelapsarian
Yes it’s always a tough call and sometimes we’ll get it wrong. 82% is a pretty good score. My scores hover between 70% and 80% most of the time, with occasional dips to 65. But I’m using the script quite a bit to generate some “words I don’t know” for another application that might well appear here soon :)
Chelae are apparently “the pincerlike organ or claw terminating certain limbs of crustaceans and arachnids.” http://www.dictionary.com/browse/chelae
Fun tool, although some are clearly scrabble distortions and not real words :) Also, your dictionary is much more up-to-date than mine, I wish I could get away with slang when playing my parents. Favorite new word so far: whigmaleerie (whim, notion). Now for the scores: between 19k and 23k, second year at university, first language English and read a fair bit.
Closer to 20k if I’m strict about having seen a word (at least root) before rather than just recognizing the form of a mineral or chemical name. Side note, you have basically nerd-sniped me and I see myself playing this far too often!
Dutch is my native language. 17k words in English…. (I wouldn’t be surprised if I’d know a similar number in Dutch, i.e. not much higher).
An easy rule-of-thumb is 1k words per year-old up to about 20 years/20k words. Of course a 1-year-old does not know 1k words yet. And things flatten out near the 20 years. But 5k words for a 5 year old, 15k for a 15 year old and 20k for a grown up is an easy to remember rule-of thumb.
I liked the script, although it made me realize I still have quite a bit to learn. 51-64% / non-native speaker.
I would love to have it give you definitions for the unrecognized words! I spent 10 minutes trying to install the Wordnik python API correctly, but the different Python versions makes my brain bleed and it’s time for bed anyway…
Don’t worry. That’s coming next. I already have it working and feeding into a twitterbot, but that is a couple of steps ahead of the blog posting (not written yet). https://twitter.com/PiWordoftheDay
Enjoyed your script. How do I print out the list of missed words with meanings. I have a dictionary text file with meanings. The structure is head word space meaning (as a text string) followed by new line. Would be helpful if words ending with -s are stripped of the -s and looked up in addition. Thanks once again for an interesting script.
Any way to accumulate unknown words over several sessions? As you may have gathered I am an absolute newbie when it comes to Python and would appreciate help. Thanks in advance
https://duckduckgo.com/?q=python+append+to+file
I already quietly added it to the github repo a few days ago https://github.com/raspitv/vocab/blob/master/vocab.py
But the software is getting ahead of the blog now, so we’ll need to wait for the next post before adding anything more.